We have been working with AKKA Services in production for more than 14 months. Because of the size of the system, we realized we needed an additional distributed computing environment to improve system scalability, fault tolerance and concurrency. For the specific project we were working on, we had to ensure the secure and efficient operation of all ERP users in automating the financial and business flows of an organization that serves a city of approximately 100,000 people.

Challenges and Issues
As a software development company, we usually outsource to third-party consultants to help with technologies where we do not have enough of experience, but in this case, we decided to use our own skills and integrate our existing code base with AKKA Services. Of course, we had to resolve many problems ourselves, but sometimes it is an even better way to understand how does framework work from inside. Here’s what we had:
Akka.Remote
- Web system
- AKKA .net services as a separate instance
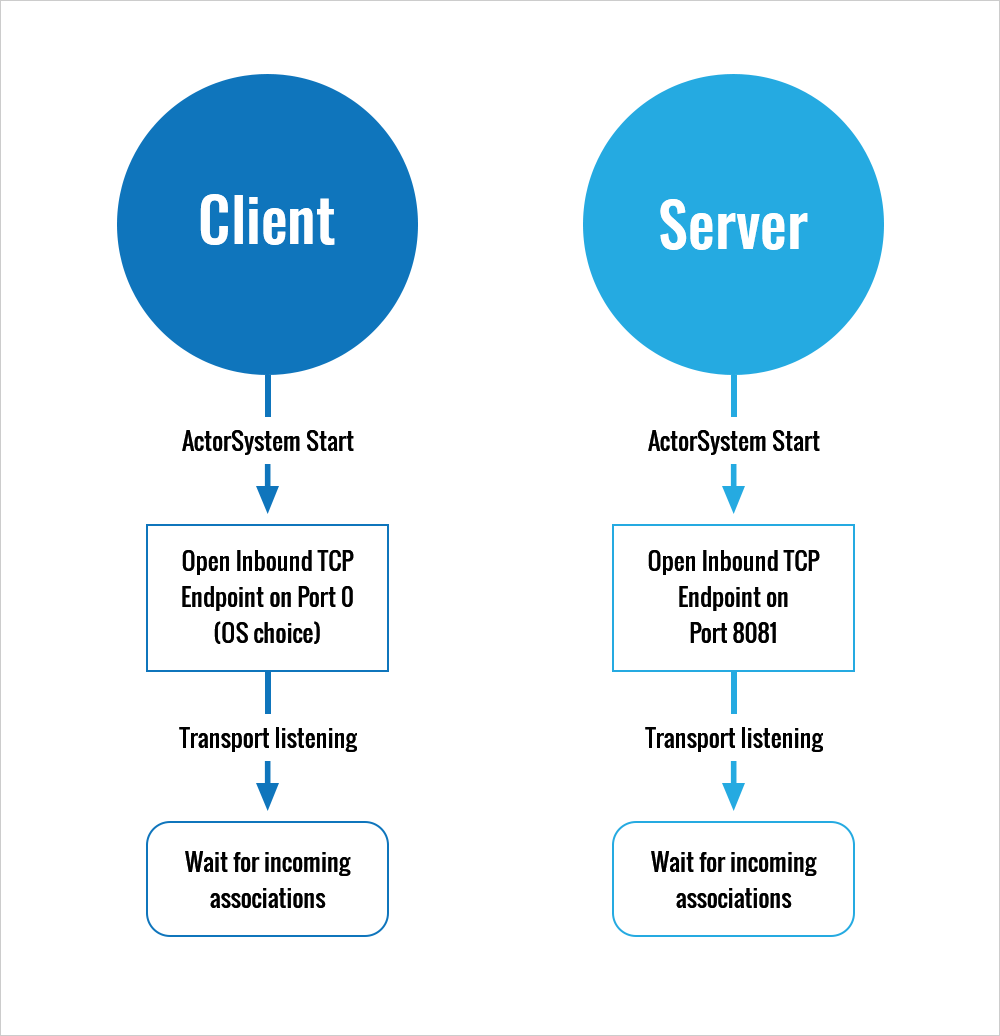
The first issues we encountered were an unstable connection between the web server and AKKA Services, uncomprehensive and hard trackable monitoring of task completion status and logging of the exceptions. To resolve that, we had to invent some workarounds. We added listeners to connection-lost events, trying to detect if the actor was alive or not. If it wasn’t, we added pulling to try to get the connection. We used SignalR-based flags to the code in order to do so.
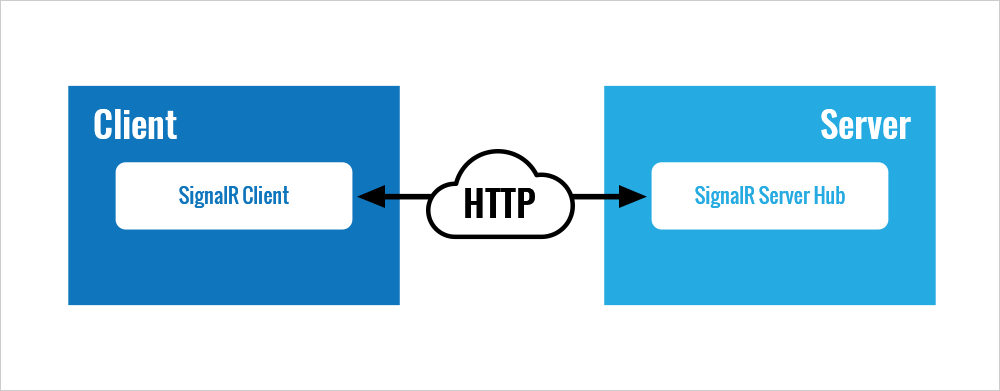
Persistence
![]()
Since we used persistent actors, which save state, we were able to get the state after restoring the connection and finish the tasks.
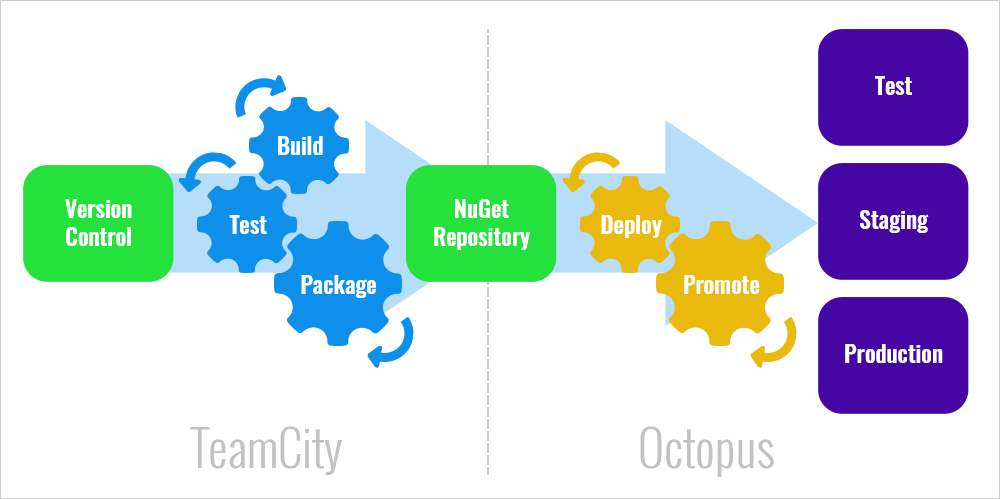
CI and deployment
With AKKA as an additional service for our system, the whole process of continuous integration (CI) became a bit more complicated. We had up to seven levels of CI and multi-branching structures like DEV/STAGE/RELEASE/PROD. In every instance, we had to be sure to test and deploy the correct version of the code.
Deploying to production without breaking the existing processes was also a challenge. Our software engineers do not resolve all questions yet, but we see that we need to move to the expanding of the current CI system using Octopus.
Conclusion
Advantages: In retrospect, the code and architecture were stable despite the complicity of AKKA architecture.
The code worked in production, and, even in live environment issues such as database timeouts and internal function crashes, the system was able to resume unfinished jobs/tasks and securely complete them.
End-users were satisfied with the performance of the web system. Front End uses Angular and system works relatively fast, but for complex calculations, (for example – validate and save 5,000 rows of Accounting Information) AKKA is what you need. Especially for finance projects, it is an extremely important advantage.
Disadvantages: The issue of deploying new functionality without breaking existing processes was not resolved.
More information in Logs would have been helpful to understand the internal exceptions happening in the AKKA processes.
Overall, we expected better performance from the messages in AKKA.
Refactoring of Akka integration code
Performance issues: We noticed that system processes message extremely slowly, which was not acceptable. Actors must work fast when receiving a message. We discovered that developers often migrated all the original code for web methods by request. After refactoring, the performance issues were resolved.
Memory usage and concurrent request conflicts:
Here’s an example of the problem: The system has a task (TaskID 1). Based on that task, an actor was created: TaskActor_1. All requests from Task 1 will work through that actor.
Even after the task is complete, we keep the actor in memory. We found that sometimes we had 10,000 active actors simultaneously.
Routing: To resolve that issue, we added a routing mechanism.
How does it work? For 10 task types, we assign 10 actors (depending on the task type). Now only these 10 actors work with all 10,000 tasks. Tasks with the same ID always go to the actor with that ID. Therefore, we have 10 active actors instead of 10,000.
An added benefit was that all requests to the same task type are now in the queue, and we don’t have to add MUTEX, semaphore or a different way to control concurrency and synchronization.
With routing, we can control the lifecycle of the actors and the performance of the system. This doesn’t resolve the issue of the hash mechanism not allowing us to automatically make the system scalable, but we’ll take care of this in the next step.
Web vs AKKA Services: Right now, we use SignalR for pooling and allow AKKA to send messages to the webserver. Web-connected to AKKA through system actor and IP address from configuration (remoting).
It is not secure if we don’t get a response in time. For example, if AKKA creates a new entity, you may get two entities instead of one.
We changed the architecture to move AKKA inside the main web server and use remoting only for specific actors, which could be located to other servers.
From the other side, we could get another problem connected to IIS; for example, when IIS switches to sleep mode. After every iteration when we are getting new experience – the code stability and quality will grow.
Next steps to improve AKKA integration
AKKA persistence: It is possible to use this feature for transaction tasks. We can locally save state and use it for rollback transactions (restore state and return in time to the previous state).
AKKA clustering: This feature allows using clusters, where AKKA services are rotating and it’s relatively easy to improve performance.
From Author: Thank you for reading this.
Do you think that the article is helpful for you? Please do not hesitate to contact us or start a discussion below (we use DISQUS).